Запрос данных из базы | Python: Django ORM
Зарегистрируйтесь для доступа к 15+ бесплатным курсам по программированию с тренажером
Одна из задач, которую берут на себя ORM – это построение произвольных SQL-запросов в базу данных. Вот как это делается с помощью Django ORM:
# SELECT * FROM users WHERE name = "John" ORDER BY last_name DESC LIMIT 10
users = User.objects.filter( # WHERE
first_name='John',
).order_by( # ORDER BY
'-last_name'
)[:10] # LIMIT
for user in users:
print(user.last_name)
Менеджер и Запросы
На текущем этапе важно познакомиться с двумя терминами, которые используются повсеместно, когда речь идёт о построении запросов в Django ORM: Менеджер (Manager) и Запрос (QuerySet). Manager отвечает за связь модели как Python-класса с фактическим представлением данных в соответствующей таблице БД, а также позволяет программисту строить запросы (QuerySets) к этой таблице и создавать в ней новые записи. Помимо построения запросов, менеджер интерпретирует их результаты. Например, представляет данные из базы в виде экземпляров класса модели. У любой модели есть хотя бы один менеджер — тот, что доступен через атрибут
Например, представляет данные из базы в виде экземпляров класса модели. У любой модели есть хотя бы один менеджер — тот, что доступен через атрибут .objects класса модели. В примере выше User.objects — менеджер модели User.
С методом .create() менеджера вы уже встречались на предыдущем уроке. Этот метод создаёт новые записи в таблице. Большинство же других методов начинают построение запроса — значения типа QuerySet. Каждый подобный метод возвращает новый QuerySet, запоминающий новые параметры будущего запроса. В примере цепочка вызовов .filter(..).order_by(..) конструирует запрос по шагам. И даже взятие среза ([:10]) только уточняет запрос, также создавая новый QuerySet.
Обратите внимание: сам SQL-запрос сразу не выполняется. Для того, чтобы выполнить SQL-запрос или, как говорят, «финализировать», нужно начать итерацию результатов или обратиться к одному из «элементов» имеющегося QuerySet по индексу. В примере SQL-запрос выполняется в тот момент, когда цикл
В примере SQL-запрос выполняется в тот момент, когда цикл for пробует получить от users первый элемент.
Построение запросов с помощью методов
Пока запрос не финализирован, его можно свободно сохранять в переменные или передавать из одного участка кода в другой и строить новые QuerySets на основе сохранённого:
johns = User.objects.filter(first_name='John') # все Джоны connors = johns.filter(last_name='Connor') # только Джоны Конноры others = johns.exclude(last_name='Connor') # Джоны, но не Конноры
Здесь представлено три QuerySets, причём второй и третий построены на основе первого. И ни один из них ещё не финализирован.
Обратите внимание: первый вызов в цепочке всегда относится к менеджеру, каким бы ни был метод
Порядок вызова методов не важен. Сначала можно сортировать, а потом фильтровать:
users = User.objects.order_by(
'-last_name', # "-" означает "по убыванию"
).filter(
first_name='John',
)
# SELECT * FROM users WHERE first_name = "John" ORDER BY last_name DESC
Django ORM самостоятельно расставит все части в правильном порядке. Однако, несмотря на такую заботу, всё же рекомендуется везде, где это возможно, соблюдать ожидаемый порядок вызовов. Это упростит чтение кода.
Однако, несмотря на такую заботу, всё же рекомендуется везде, где это возможно, соблюдать ожидаемый порядок вызовов. Это упростит чтение кода.
Многие вызовы могут накапливаться. Цепочка из filter породит в SQL-запросе одну часть WHERE, где все условия объединены с помощью оператора AND:
User.objects.filter(first_name='John').filter(age=34).exclude(city='Moscow') # WHERE first_name = "John" AND age = 34 AND NOT (city = "Moscow")
Но некоторые методы не накапливаются. Например, каждый последующий вызов .order_by() заменяет ранее указанное правило сортировки на новое! Это позволяет описать и сохранить сортировку по умолчанию, оставив возможность её подменить, если понадобится.
В языке запросов Django ORM есть по методу на каждую часть SQL. Некоторые из них в таблице ниже:
| метод | SQL |
|---|---|
.filter(), .exclude() | WHERE |
. | ORDER |
[:] | LIMIT/OFFSET |
 order_by()
order_by()Мы рассмотрим только некоторые из них. Остальные достаточно легко понять из документации, если вы знаете SQL. Если это не так, рекомендуем пройти курс основы баз данных.
.filter()
.exclude() во всём похож на .filter() и лишь добавляет NOT к условию, то есть инвертирует оное. Взглянем на примеры фильтрации:# WHERE votes = 100 User.objects.filter(votes=100) # WHERE votes >= 100 User.objects.filter(votes__gte=100)
Обратите внимание на то, как закодировано нестрогое равенство: «__gte» — двойное подчёркивание плюс сокращение от «greater than or equal». В Django условия принято указывать в виде именованных аргументов, а в их именах нельзя использовать символы вроде «<«, поэтому потребовались сокращения.
Помимо проверок на неравенство, таких как __gte, Django поддерживает множество других lookups. Вот некоторые из них:
User.objects.filter(
id__in=[45, 101, 512], # равно одному из значений списка (входит В список)
first_name__iexact='John', # равно без учёта регистра
age__range=(18, 21), # входит в диапазон 18..21
middle_name__isnull=True, # необязательное поле не заполнено
last_name__icontains='ibn' # содержит подстроку без учёта регистра
)
Менеджеры и итерация
Выше было сказано, что QuerySet превращается в SQL-запрос при обращении к его элементам по индексу или при запуске процесса итерации. К менеджеру это, увы, не относится и для того, чтобы сделать запрос, нужен хотя бы какой-нибудь QuerySet.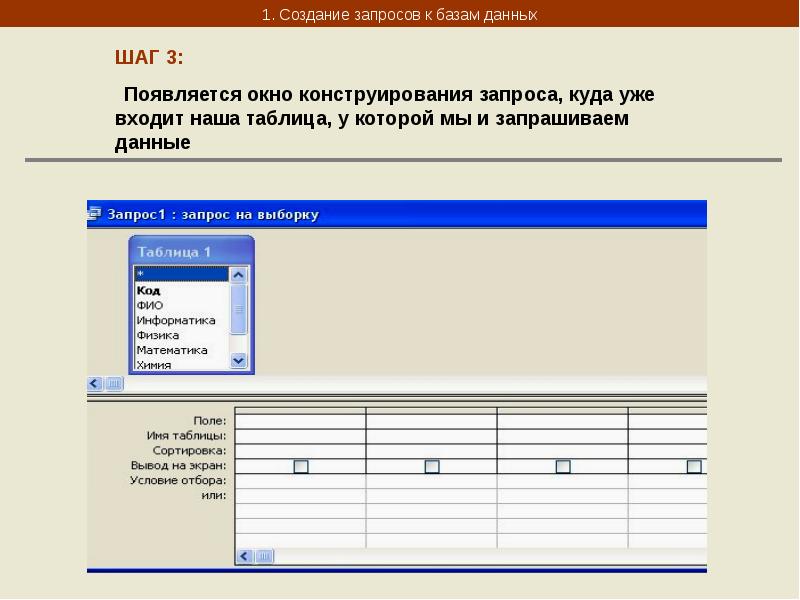
Именно поэтому периодически возникают ошибки вроде «‘Manager’ is not iterable» или «‘Manager’ is not subscriptable» в процессе выполнения кода вида for u in User.objects: .. или User.objects[0]. Как только вы вызовите хотя бы один метод, уточняющий запрос, вы получите в ответ QuerySet и проблема решится сама собой. Взятие среза к менеджеру, увы, не применимо, потому что это подвид обращения по индексу (subscription protocol).
Если же вам не нужно уточнять запрос и вы действительно хотите работать со всеми записями, то используйте метод .all(), который для менеджера вернёт QuerySet без дополнительных условий. Если же вызвать .all() у имеющегося QuerySet, то тот просто «вернёт себя». Так что бояться метода .all() не следует, его вызов вовсе не означает «запросить всё»!
Зачем?
Для чего нужен такой язык, почему недостаточно SQL? На это есть несколько разных причин:
- Универсальность.
 Django ORM способна генерировать SQL, подходящий под конкретную базу данных. Построение запросов же не привязано к базе данных. Хотя это не отменяет ситуаций, в которых приходится выполнять «сырые» запросы в базу данных.
Django ORM способна генерировать SQL, подходящий под конкретную базу данных. Построение запросов же не привязано к базе данных. Хотя это не отменяет ситуаций, в которых приходится выполнять «сырые» запросы в базу данных.
 Django ORM способна генерировать SQL, подходящий под конкретную базу данных. Построение запросов же не привязано к базе данных. Хотя это не отменяет ситуаций, в которых приходится выполнять «сырые» запросы в базу данных.
Django ORM способна генерировать SQL, подходящий под конкретную базу данных. Построение запросов же не привязано к базе данных. Хотя это не отменяет ситуаций, в которых приходится выполнять «сырые» запросы в базу данных.Открыть доступ
Курсы программирования для новичков и опытных разработчиков. Начните обучение бесплатно
- 130 курсов, 2000+ часов теории
- 1000 практических заданий в браузере
- 360 000 студентов
Электронная почта *
Отправляя форму, вы принимаете «Соглашение об обработке персональных данных» и условия «Оферты», а также соглашаетесь с «Условиями использования»
Наши выпускники работают в компаниях:
Отсылаем запрос через БД-интерфейс Адаптера
Для отправки и приема сообщений СМЭВ можно использовать несколько интерфейсов, в том числе интерфейс базы данных (интерфейс БД).
Интерфейс БД предназначен для обеспечения взаимодействия информационных систем Участника межведомственного электронного взаимодействия (далее «Участника») с Адаптером СМЭВ посредством SQL-запросов.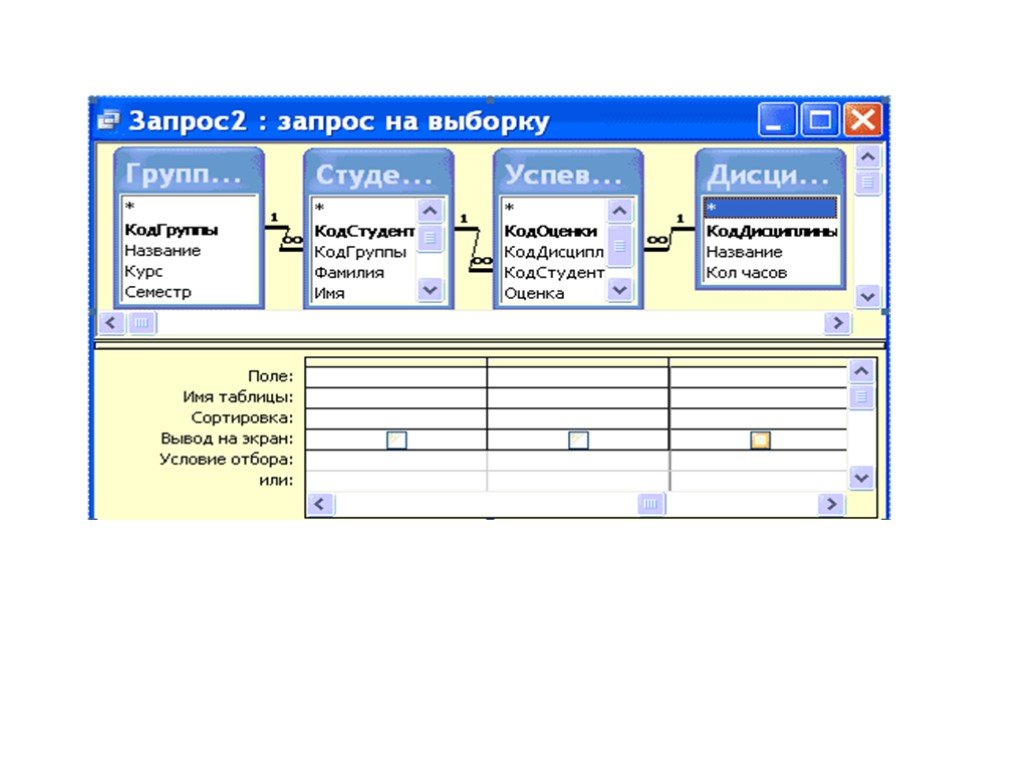
Рассмотрим порядок отправки запроса в СМЭВ через интерфейс БД Адаптера СМЭВ.
Описание интерфейса базы данных Адаптера СМЭВ
Интерфейс базы данных Адаптера СМЭВ, в общем случае, представляет собой совокупность таблиц БД:
«Send_Table» — предназначена для временного хранения в Адаптере СМЭВ исходящих сообщений одной информационной системы Участника. С точки зрения информационной системы Участника, эта таблица является исходящей очередью сообщений.
«Receive_Table» — предназначена для временного хранения в Адаптере СМЭВ входящих сообщений для одной информационной системы Участника. Ваша информационная система будет выбирать входящие сообщения из этой таблицы.
Примечание: наименования таблиц «Send_Table» и «Receive_Table» приведены в качестве примера, но вы можете использовать любые наименования на свое усмотрение.
Структура таблицы «Send_Table»:
|
№ |
Имя поля |
Тип данных |
PK |
Not Null |
Unique |
Описание поля |
|
1 |
id |
text |
N |
N |
N |
Клиентский идентификатор запроса |
|
2 |
content |
text |
N |
Y |
N |
Сообщения в виде xml-строки: — запросы, отправляемые в СМЭВ; — ответы на запросы, отправляемые в СМЭВ |
|
3 |
status |
text |
N |
Y |
|
Статус отправки сообщения в Адаптер СМЭВ. Поле принимает одно из следующих значений: — NEW. Новое сообщение на отправку. Данное значение устанавливает Информационная система Участника; — SUCCESS. Сообщение принято Адаптером СМЭВ. Данное значение устанавливает Адаптер СМЭВ; — FAIL. Ошибка обработки сообщения в Адаптере СМЭВ. Данное значение устанавливает Адаптер СМЭВ. |
|
4 |
created_at |
timestamp |
N |
Y |
N |
Метка времени создания записи в таблице |
|
5 |
uid |
bigserial |
Y |
Y |
Y |
Первичный ключ таблицы |

Структура таблицы «Receive_Table»:
|
№ |
Имя поля |
Тип данных |
PK |
Not Null |
Unique |
Описание поля |
|
1 |
id |
text |
N |
N |
N |
Клиентский идентификатор запроса |
|
2 |
node_id |
text |
N |
N |
N |
Клиентский идентификатор узла информационной системы |
|
3 |
content |
text |
N |
Y |
N |
Сообщения в виде xml-строки: — запросы, поступившие из СМЭВ; — ответы на запросы, поступившие из СМЭВ; — бизнес-ошибки обработки сообщений в Адаптере СМЭВ либо поступившие из СМЭВ;
— статусные сообщения, поступившие из СМЭВ. |
|
4 |
ref_id |
text |
N |
N |
N |
Ссылка на начальное сообщение в последовательности |
|
5 |
ref_group_id |
text |
N |
N |
N |
Идентификатор группы сообщения |
|
6 |
created_at |
timestamp |
N |
Y |
N |
Метка времени создания записи в таблице |
|
7 |
uid |
bigserial |
Y |
Y |
Y |
Первичный ключ таблицы |
Как создать таблицы БД
Для создания таблицы БД используется pgAdmin 4. Запустите его через меню «Пуск/PostgreSQL 12/pgAdmin 4»:
Запустите его через меню «Пуск/PostgreSQL 12/pgAdmin 4»:
В открывшемся pgAdmin 4 авторизуйтесь, выберите базу данных «smev_adapter_single». Затем в меню «Tools» выберите пункт «Query Tool»:
В окне запросов введите команду:
Скачать
И выполните скрипт, нажав на панели инструментов кнопку запуска :
В результате выполнения запроса в схеме public будет создана новая таблица «mnemonic_send»:
Затем в окне запросов введите команду:
Скачать
И вновь выполните запуск скрипта:
В результате выполнения этой команды в схеме public будет создана таблица «mnemonic_receive»:
Как включить и настроить способ использования ИС «База данных»
Для включения способа использования «База данных» зайдите в веб-интерфейс Адаптера СМЭВ и авторизуйтесь под учётной записью «admin».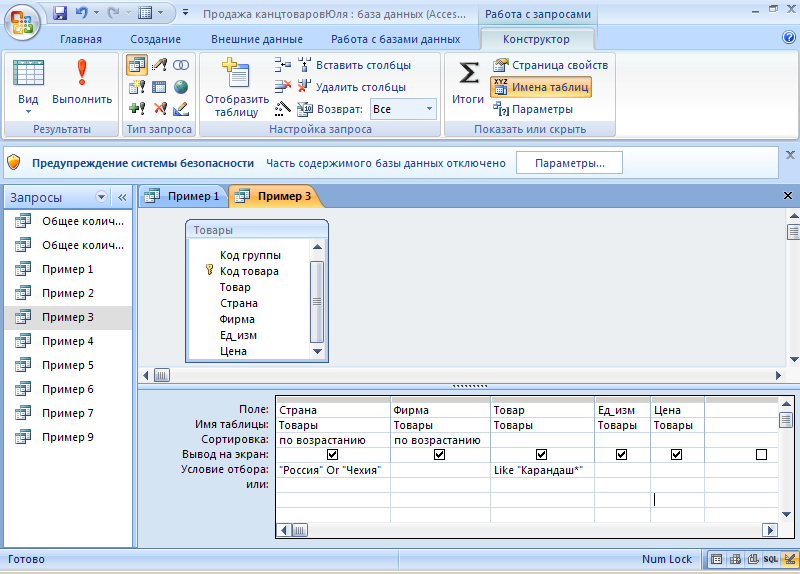 Затем перейдите на страницу «Информационные системы» и выберите из выпадающего списка «1.2. Способ использования» значение «База данных»:
Затем перейдите на страницу «Информационные системы» и выберите из выпадающего списка «1.2. Способ использования» значение «База данных»:
После этого нажмите кнопку «Сохранить» в нижней части страницы. Затем перейдите на этой же странице в раздел «6. Модуль интеграции через базу данных» и заполните поля своими данными:
На что следует обратить внимание при заполнении этого раздела:
- в поле «6.1. Адрес» замените адрес по умолчанию «localhost» на IP адрес сервера баз данных и укажите имя своей базы данных;
- в поле «6.3 Имя пользователя БД» укажите имя учётной записи базы данных;
- в поле «6.4. Пароль БД» введите пароль учётной записи базы данных;
- в поле «6.5. Имя таблицы для отправленных сообщений» укажите имя таблицы для исходящих сообщений;
- в поле «6.6. Имя таблицы для принятых сообщений» укажите имя таблицы для входящих сообщений.
После ввода всех данных нажмите кнопку «Сохранить».
Как сформировать сообщение
При подготовке к отправке запроса вам необходимо сформировать (в редакторе) XML-конверт сообщения «ClientMessage», в соответствии с XSD-схемами Адаптера СМЭВ. Данный конверт должен содержать все обязательные элементы, исходя из требований к направляемому сообщению.
Структура XML-конверта сообщения «ClientMessage», которая выглядит так:
Скачать
Для формирования значения тега «clientId» можно воспользоваться любым из онлайн генераторов UUID.
Как отправить запрос через Адаптер СМЭВ
Поместите сформированный XML-конверт сообщения «ClientMessage» в поле «content» и в теге «id» укажите тот же идентификатор, что и в теге «clientId» XML-конверта.
У вас должен получиться следующий SQL-запрос для отправки сообщения:
Скачать
Теперь выполните подготовленный запрос:
Проверьте статус запроса в таблице «mnemonic_send» посредством выполнения запроса:
Вы увидите статус своего запроса:
Запрос через интерфейс базы данных Адаптера СМЭВ отправлен.
ЛК УВ предоставляет возможность просмотра информации о сеансах обмена в СМЭВ.
Информация о сеансе обмена включает в частности:
- СМЭВ-идентификатор инициирующего запроса;
- время получения запроса в СМЭВ;
- продолжительность обработки на стороне СМЭВ.
Чтение данных из баз данных SQL
Чтение данных из баз данных SQLУзнайте, как писать SQL-запросы в Retool для чтения данных.
Для чтения из базы данных вы можете написать операторы SQL. Например, этот запрос выбирает всех активных или неактивных пользователей в зависимости от того, установлен ли флажок.
выберите * из пользователей, где активно = {{checkbox1.value}};
Назовите запрос getUsers , сохраните его и получите доступ к его результатам в другом месте как getUsers.data . Запросы SQL возвращают данные в формате на основе столбцов:
{
"столбец1": [1, 2, 3],
"столбец2": [1, 2, 3],
. ..
}
 ..
}
..
}
Данные запросов SQL , а не возвращаются в виде массива объектов. Чтобы получить доступ к данным в виде массива объектов, используйте метод formatDataAsArray .
Примеры более сложных SQL-запросов в Retool см. в памятке по SQL.
Чтобы предотвратить внедрение SQL, Retool преобразует запросы SQL в подготовленные операторы. Точное поведение запроса зависит от вашего конкретного драйвера базы данных. Однако большинство баз данных не поддерживают подготовленные операторы с динамическими именами столбцов или динамическими именами таблиц, потому что в таких случаях трудно предотвратить внедрение SQL.
Это означает, что следующий запрос не работает в PostgreSQL, поскольку имя таблицы является динамическим, а PostgreSQL не поддерживает динамические имена таблиц в подготовленных операторах.
выберите * из {{textinput1.value === 'getUsers' ? 'пользователи' : 'платежи'}}
Вместо этого следует написать два запроса:
select * from users
выбрать * из платежей
Затем вы можете сослаться на правильный оператор SQL в зависимости от значения textinput1 :
{
{
textinput1. value === "getUsers" ? пользователи.данные : платежи.данные;
}
}
 value === "getUsers" ? пользователи.данные : платежи.данные;
}
}
value === "getUsers" ? пользователи.данные : платежи.данные;
}
}
Администраторы могут отключить подготовленные операторы для ресурса, установив флажок Отключить преобразование запросов в подготовленные операторы на странице сведений о ресурсе. Это отключает защиту от SQL-инъекций и подвергает ресурс атакам с SQL-инъекциями, поэтому его следует использовать с осторожностью.
Если вы отключите подготовленные операторы, вам может потребоваться обновить запросы, использующие JavaScript, в течение {{ }} , потому что некоторые базы данных ожидают заполнители подготовленных операторов без кавычек или выполняют преобразования типов в подготовленных операторах.
Например, если разрешены подготовленные операторы, следующий запрос PostgreSQL не должен заключать в кавычки заполнитель подготовленного оператора.
выберите идентификатор, имя, фамилия
от пользователей ты
где u.id = {{ numberInput1. value }};
 value }};
value }};
Когда подготовленные операторы отключены, заполнитель требует кавычек.
выберите идентификатор, имя, фамилия
от пользователей ты
где u.id = '{{ numberInput1.value }}'
Обратитесь к документации вашей базы данных по подготовленным операторам, чтобы подтвердить предполагаемое использование.
Обновлено 1 день назад
Решения — запросы к базе данных с R
Существует множество способов запроса данных с помощью R. В этой статье показаны три наиболее распространенных способа:
- Использование
DBI - Использование синтаксиса
dplyr - Использование ноутбуков R
Фон
Несколько пакетов упрощают использование баз данных с R. Приведенные ниже примеры запросов демонстрируют некоторые возможности этих пакетов R.
- ДБИ. Спецификация
DBIпретерпела множество недавних улучшений. При работе с базами данных всегда следует использовать пакеты, совместимые с DBI. - dplyr и
dbplyr. Пакетdplyrтеперь имеет обобщенный бэкенд SQL для взаимодействия с базами данных, а новый пакетdbplyrпереводит код R в варианты, специфичные для базы данных. На момент написания этой статьи варианты SQL поддерживаются для следующих баз данных: Oracle, Microsoft SQL Server, PostgreSQL, Amazon Redshift, Apache Hive и Apache Impala. Со временем последуют другие. - одбк. Пакет
odbcR предоставляет стандартный способ подключения к любой базе данных, если у вас установлен драйвер ODBC. ПакетodbcR соответствует стандартуDBIи рекомендуется для соединений ODBC.
 При работе с базами данных всегда следует использовать пакеты, совместимые с
При работе с базами данных всегда следует использовать пакеты, совместимые с Компания Posit также усовершенствовала свои продукты, чтобы они лучше работали с базами данных.
- RStudio IDE (версия 1.1 и новее). С помощью RStudio IDE вы можете подключаться, исследовать и просматривать данные в различных базах данных. В среде IDE есть мастер для настройки новых подключений и вкладка для просмотра установленных подключений. Эти функции расширяемы и будут работать с любым пакетом R, имеющим контракт на подключение.
- Профессиональные драйверы Posit. Если вы используете RStudio Desktop Pro или другие профессиональные продукты Posit, вы можете бесплатно загрузить драйверы Posit Professional на тот же компьютер, на котором установлены эти продукты. В приведенных ниже примерах используется драйвер Oracle ODBC. Если вы используете инструменты с открытым исходным кодом, вы можете принести свой собственный драйвер или использовать пакеты сообщества — существует множество драйверов с открытым исходным кодом и пакетов сообщества для подключения к различным базам данных.
 В среде IDE есть мастер для настройки новых подключений и вкладка для просмотра установленных подключений. Эти функции расширяемы и будут работать с любым пакетом R, имеющим контракт на подключение.
В среде IDE есть мастер для настройки новых подключений и вкладка для просмотра установленных подключений. Эти функции расширяемы и будут работать с любым пакетом R, имеющим контракт на подключение.Использование баз данных с R — обширная тема, и предстоит еще много работы. В предыдущем сообщении в блоге обсуждалось наше видение.
Пример: Запрос данных банка в базе данных Oracle
В этом примере мы будем запрашивать банковские данные в базе данных Oracle.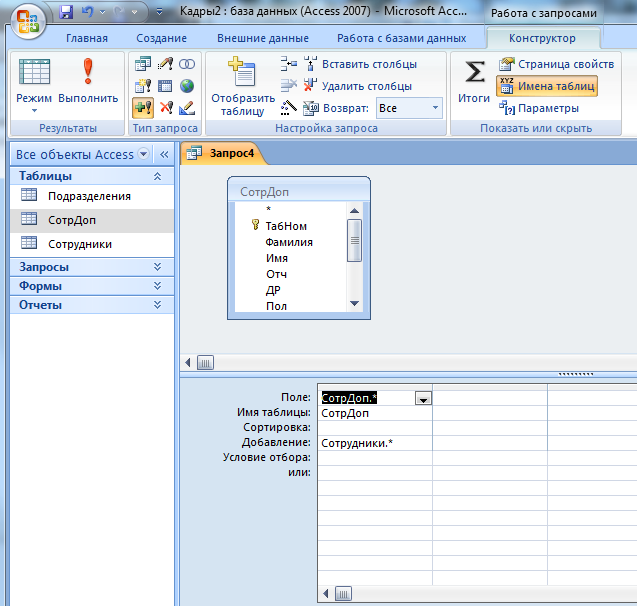 Мы подключаемся к базе данных с помощью пакетов
Мы подключаемся к базе данных с помощью пакетов DBI и odbc . Для этого конкретного подключения требуется драйвер базы данных и имя источника данных (DSN), которые были настроены системным администратором. Ваше подключение может использовать другой метод.
библиотека (DBI) библиотека (dplyr) библиотека (dbplyr) библиотека (odbc) con <- dbConnect(odbc::odbc(), "БД Oracle")
1. Запрос с использованием
DBI Вы можете запросить данные с помощью DBI с помощью функции dbGetQuery() . Просто вставьте свой код SQL в функцию R в виде строки в кавычках. Этот метод иногда называют проходом через код SQL и, вероятно, это самый простой способ запроса ваших данных. Следует проявлять осторожность, чтобы избежать кавычек по мере необходимости. Например, «да» записывается как «да» .
dbGetQuery(con,' выберите "month_idx", "год", "месяц", сумма (случай, когда "term_deposit" = \'yes\', затем 1.
 0, иначе 0.0 конец) как подписка,
количество (*) как общее
из "банка"
группировать по "month_idx", "году", "месяцу"
')
0, иначе 0.0 конец) как подписка,
количество (*) как общее
из "банка"
группировать по "month_idx", "году", "месяцу"
') 2. Запрос с использованием синтаксиса dplyr
Вы можете написать свой код в синтаксисе dplyr , и dplyr переведет ваш код в SQL. Написание запросов с синтаксисом dplyr дает несколько преимуществ: вы можете использовать один и тот же согласованный язык как для объектов R, так и для таблиц базы данных, не требуется знание SQL или конкретного варианта SQL, и вы можете воспользоваться тем фактом, что dplyr использует ленивую оценку. Синтаксис dplyr легко читается, но вы всегда можете проверить перевод SQL с помощью функция show_query() .
q1 <- tbl(con, "bank") %>%
group_by(month_idx, год, месяц) %>%
подведем итог(
подписаться = сумма (ifelse (term_deposit == "да", 1, 0)),
всего = n())
show_query(q1) ВЫБЕРИТЕ «month_idx», «год», «месяц», СУММА (СЛУЧАЙ, КОГДА («term_deposit» = «да»), ТОГДА (1.
 0) ИНАЧЕ (0.0) КОНЕЦ) КАК «подписаться», СЧЕТЧИК (*) КАК «всего»
ОТ («банк»)
ГРУППА ПО "month_idx", "год", "месяц"
0) ИНАЧЕ (0.0) КОНЕЦ) КАК «подписаться», СЧЕТЧИК (*) КАК «всего»
ОТ («банк»)
ГРУППА ПО "month_idx", "год", "месяц" 3. Запрос с помощью R Notebooks
Знаете ли вы, что код SQL можно запускать в фрагменте кода R Notebook? Чтобы использовать SQL, откройте R Notebook в RStudio IDE в разделе 9.0017 Меню «Файл» > «Новый файл» . Начните новый фрагмент кода с {sql} и укажите свое соединение с параметром фрагмента кода connection=con . Если вы хотите отправить вывод запроса в кадр данных R, используйте output.var = "mydataframe" в параметрах фрагмента кода. Когда вы укажете output.var , вы сможете использовать выходные данные в последующих фрагментах кода R. В этом примере мы используем вывод ggplot2 .
```\{sql, connection=con, output.var = "mydataframe"\}
ВЫБЕРИТЕ «month_idx», «год», «месяц», СУММА (СЛУЧАЙ, КОГДА («term_deposit» = «да»), ТОГДА (1. 0) ИНАЧЕ (0.0) КОНЕЦ) КАК «подписаться»,
COUNT(*) КАК "всего"
ОТ («банк»)
ГРУППА ПО "month_idx", "год", "месяц"
```  0) ИНАЧЕ (0.0) КОНЕЦ) КАК «подписаться»,
COUNT(*) КАК "всего"
ОТ («банк»)
ГРУППА ПО "month_idx", "год", "месяц"
```
0) ИНАЧЕ (0.0) КОНЕЦ) КАК «подписаться»,
COUNT(*) КАК "всего"
ОТ («банк»)
ГРУППА ПО "month_idx", "год", "месяц"
``` ```\{г\}
библиотека (ggplot2)
ggplot(mydataframe, aes(всего, подписка, цвет = год)) +
геометрическая_точка() +
xlab("Всего контактов") +
ylab("Подписки на срочный депозит") +
ggtitle("Объем контактов")
``` Преимущество использования SQL в фрагменте кода заключается в том, что вы можете вставлять свой код SQL без каких-либо изменений. Например, вам не нужно экранировать кавычки. Если вы используете пресловутый код спагетти , который состоит из сотен строк, то фрагмент кода SQL может быть хорошим вариантом. Еще одно преимущество заключается в том, что код SQL в фрагменте кода выделяется, что упрощает его чтение. Для получения дополнительной информации о механизмах SQL см. эту страницу о механизмах языка Knitr.
Резюме
Не существует единственного наилучшего способа запроса данных с помощью R.